
參加人數
Intelligent Vision System Lab (IVS), National Chiao Tung University (NCTU), Taiwan
The Intelligent Vision System Lab (IVS) at National Chiao Tung University is directed by Professor Jiun-In Guo. We are tackling practical open problems in autonomous driving research. We are focused intelligent vision processing system, applications, and SoC exploiting deep learning technology.
Web Site: http://ivs.ee.nctu.edu.tw/ivs/
Pervasive Artificial Intelligence Research (PAIR) Labs, Ministry of Science and Technology, Taiwan.
The Pervasive AI Research (PAIR) Labs, a national research lab funded by the Ministry of Science and Technology, Taiwan, is commissioned to achieve academic excellence, nurture local AI talents, build international linkage, and develop pragmatic approaches in the areas of applied AI technologies toward services, products, workflows, and supply chains innovation and optimization. PAIR Labs is constituted of 13 distinguished research institutes to conduct research in applied AI areas.
Web Site: https://pairlabs.ai/

Award Winner • Champion: R.JD • Runner-up: Omission • 3rd-place: Omission MMSP 2019 Paper Invitation Those teams who achieve mAP that is better than 0.46 in the final are invited to publish papers in the MMSP competition special session held in MMSP 2019. The teams are listed below: • R.JD • nctuai • chenjiaqi • IMMVP Final Evaluation Result • R.JD (The College of Information Engineering of Xiangtan University) --mAP: 0.5389 --Model Size(MByte): 124.6 --Complexity(GOPS/frame): 43.6 --Speed(ms/frame): 460.5 --Award: Champion --MMSP paper invitation: Yes •nctuai (Department of Electrical Engineering, National University of Tainan) --mAP: 0.4760 --Model Size(MByte): 195.2 --Complexity(GOPS/frame): 490.1 --Speed(ms/frame): 1338.9 --Award: Not qualified (mAP<0.50) --MMSP paper invitation: Yes •chenjiaqi (The College of Information Engineering of Xiangtan University) --mAP: 0.4619 --Model Size(MByte): 114.0 --Complexity(GOPS/frame): 339.5 --Speed(ms/frame): 1195.0 --Award: Not qualified (mAP<0.50) --MMSP paper invitation: Yes •IMMVP (Institute of Information Science, Academia Sinica) --mAP: 0.4605 --Model Size(MByte): 57.1 --Complexity(GOPS/frame): 724.9 --Speed(ms/frame): 510.3 --Award: Not qualified (mAP<0.50) --MMSP paper invitation: Yes •NPUST-MIS-No.1 (Department of Management Information Systems, National Pingtung University of Science and Technology) --mAP: 0.4396 --Model Size(MByte): 238.4 --Complexity(GOPS/frame): 115.6 --Speed(ms/frame): 514.5 --Award: Not qualified (mAP<0.50) --MMSP paper invitation: -----
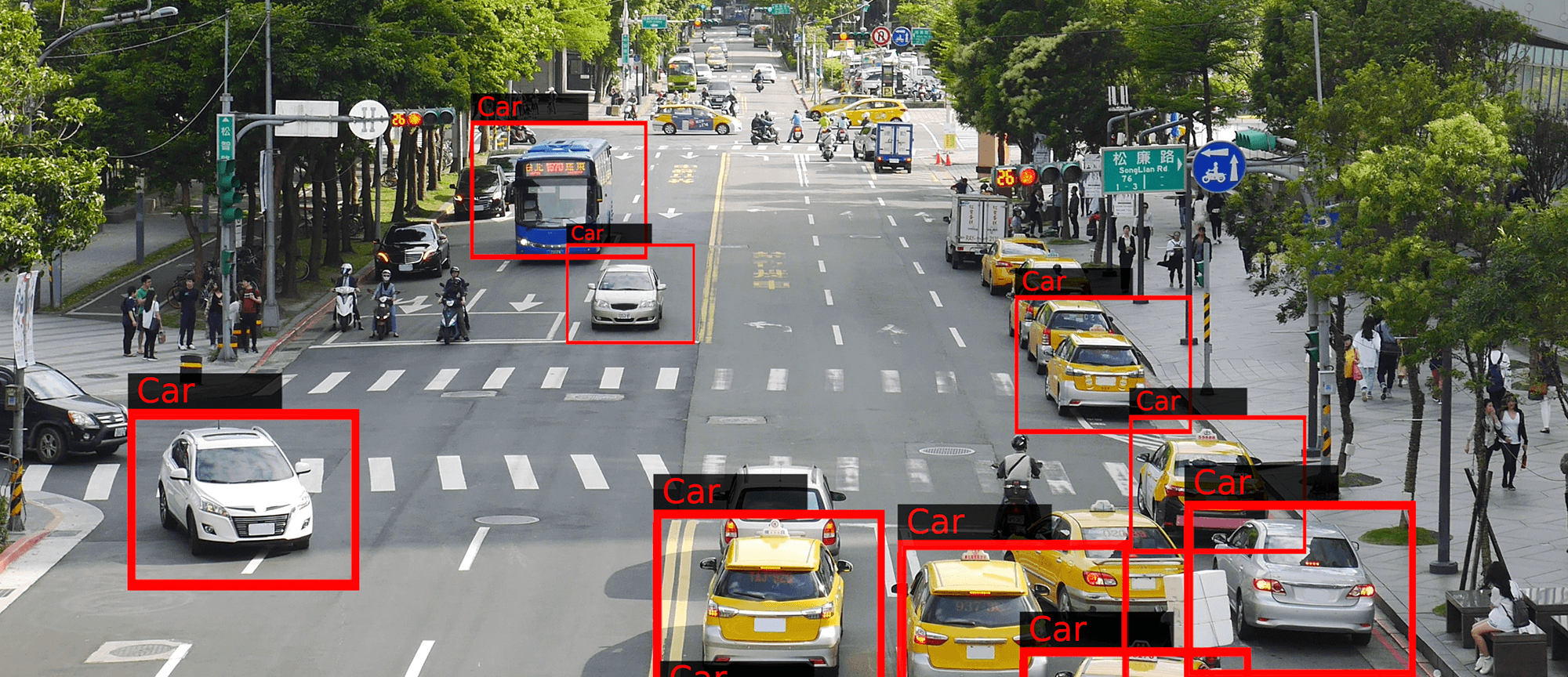
Object detection in computer vision area has been extensively studied and making tremendous progress in recent years using deep learning methods. However, due to the heavy computation required in most deep learning based algorithms, it is hard to run these models on embedded systems, which have limited computing capabilities.
In this competition, we encourage the participants to design object detection models that do not only fit for embedded systems but also achieve high accuracy at the same time.
The goal is to design a lightweight deep learning model suitable for constrained embedded system design. We focus on model size, computation complexity and performance optimization on NVIDIA Jetson TX2.
Given the test image dataset, participants are asked to detect objects belonging to the following three classes {pedestrian, vehicle, rider} in each image, including class, bounding box, and confidence.
This competition is divided into two stages: qualification and final competition.
Qualification Competition: all participants submit their answers online. A score is calculated. The top 10 teams would be qualified to enter the final round of competition.
Final Competition: the final score will be evaluated over NVIDIA Jetson TX2 for the final score.
Champion: One team ($USD 1,500)
Runner-up: One team ($USD 1,000)
3rd-place: One team ($USD 750)
| Date | Activity |
|---|---|
| 2019/06/01 | Qualification Competition Start, Release Public Testing Data |
| 2019/07/14 | Release Testing Data for Qualification |
| 2019/07/21 15:59:59 UTC | Qualification Competition End |
| 2019/07/22 | Final Competition Start, Release Private Testing Data for Final |
| 2019/07/28 15:59:59 UTC | Final Competition End |
| 2019/08/09 | Award Announcement |
Qualification Competition
The grading rule is based on MSCOCO object detection rule.
mean Average Precision (mAP) is used to evaluate the result.
Intersection over union (IoU) threshold is set at 0.5
The resulting average precision (AP) of each class will be calculated and the mean AP (mAP) over all classes is evaluated as the key metric.
The public test dataset will be released at the beginning of the competition. The participants can submit the results to get the scores online to realize their ranks among all teams.
Besides, during the qualification competition period, each team has to submit a team composition document, including team name, leader, team members, affiliation, and contact information, etc.
Another private test dataset will be released a week before the end of the qualification competition and all participants have to submit the results for the private test dataset in a week and only the result for private test dataset will be graded for the qualification.
Final Competition
The finalists have to hand in a clone image of the eMMC partition on the Nvidia Jetson TX2 board that executes the object detection package. We will restore the submitted image to a Jetson TX2 board and grade the final score by running the model according to the following formula:
Example of computing Model size:
For a convolution layer with eight-bit parameters of (input size, output size, kernel size) = $(W_i×H_i×C_i, W_o×H_o×C_o, W_k×H_k)$ with bias added, the model size of this layer will be $$(W_k×H_k×C_i+1)×C_o×8$$
For a fully-connected layer with eight-bit parameters of input size $W_i×H_i×C_i$, output size $W_o×H_o×C_o$, with bias added, the model size of this layer will be $$(W_i×H_i×C_i+1)×W_o×H_o×C_o×8$$
Example of computing number of operations:
For a convolution layer of input size $W_i×H_i×C_i$, output size $W_o×H_o×C_o$, kernel size $W_k×H_k$, with bias added, the total GOPs/frame for this layer will be $$(W_k×H_k×C_i×2+1)×W_o×H_o×C_o$$.
For a fully-connected layer of input size $W_i×H_i×C_i$, output size $W_o×H_o×C_o$, with bias added, the total GOPs/frame for this layer will be $$(W_i×H_i×C_i×2+1)×W_o×H_o×C_o$$
A technical report is required to reveal the model structure, complexity, and execution efficiency, etc. This report will be investigated and published in IEEE MMSP proceeding if it passes the review procedure.